
【JavaScript】window.btoa(‘日本語’) する
問題
JavaScriptでbase64エンコード、デコードをするなら、window.btoa, window.atob がありますよね。
window.btoa('Hello!'); // → "SGVsbG8h"
window.atob('SGVsbG8h'); // → "Hello!"
日本語入れたらエラーになるんですけど、だめなんですか。
window.btoa('あいうえお'); // → x
// Error: String contains an invalid character
答え
殆どのブラウザでは、window.btoa のパラメータにユニコードの文字列を指定して呼び出すと、例外「範囲外 (Out Of Range)」が返ります。
https://developer.mozilla.org/ja/docs/Web/API/window.btoa#Unicode_Strings
window.btoa(‘日本語’) は通常無理だよとのこと。ついでに、btoa(“\u65e5\u672c\u8a9e”)もだめ
ただ、これなら期待した動作をする。
window.btoa(unescape(encodeURIComponent('日本語'))); // → "5pel5pys6Kqe"
decodeURIComponent(escape(window.atob('5pel5pys6Kqe'))); // → "日本語"
とりあえず期待した動作ができた。
なんでこれでいいの?
上の引用元ページ(MDN)にも掲載されている解決方法だが、「これで正しい」とは書いていない。
今のところはこれでうまくいっちゃうよ ということなのだが、詳細は以下のようになる。
encodeURIComponent
encodeURIComponentは最新のECMAScriptの仕様に定義があり、UTF-8でのURI用の%エンコードをする。
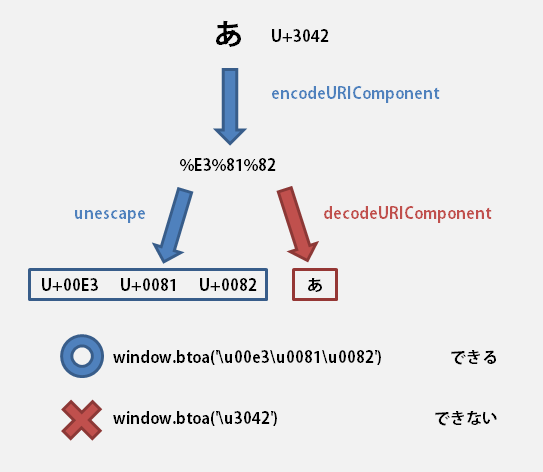
encodeURIComponentにUnicodeのU+3042(= “\u3042” = あ)をエンコードしてもらうと、こうなる。
encodeURIComponent('\u3042'); // → "%E3%81%82"
encodeURIComponent('あ'); // → "%E3%81%82"
たしかにUTF-8の”あ”の16進表現は 0xE3 0x81 0x82 (e38182) である(参考)。
ECMAScriptの定義があいまいで、encodeURIComponentは「特定の文字を」置き換えるそうだが、非ASCII文字がエンコードされる様子である。
unescape
一方、escape/unescape関数だが、最新のECMAScriptの仕様には定義がない。非推奨で、仕様からはずされ、実装は必須ではないとある。とはいえ、現段階でescape/unescape関数が即座に廃止されるのは考えにくい。
unescape関数は、パーセントエンコーディングされた文字列をアンエスケープする。一般的なパーセントエンコーディング(%XX)のみでなく、ユニコードパーセントエンコーディング(%uXXXX)も処理する。
>>> var e = encodeURIComponent('\u3042'); console.log(e);
%E3%81%82
>>> var u = unescape(e); console.log(u);
"ã" ← テキストとして見えないけど3文字ある
上の変数uに代入された文字列は、ASCIIのE3、81、82の文字である。
>>> u.charCodeAt(0).toString(16); "e3" >>> u.charCodeAt(1).toString(16); "81" >>> u.charCodeAt(2).toString(16); "82"
unescapeするのは、decodeURIComponentするのとだいぶ違う。decodeURIComponentは渡された文字列をUTF-8として扱う。3つのエンコードされた文字はまた元のUTF-8の1文字に戻される。unescapeは単純にひとつずつ文字として返す。
こうして、unescape(encodeURIComponent())された文字列は、元のUTF-8の文字列の各バイトのASCII表現となる。
まとめ
以下のように変換されて、window.btoaに渡しても大丈夫な形になっていたのでした。
参考
http://ecmanaut.blogspot.jp/2006/07/encoding-decoding-utf8-in-javascript.html
コメント